What Does 'P vs. NP' Mean for the Rest of Us?
2010年8月25日 05:43
——A proposed "proof" is probably a bust--but even failed attempts can advance computer science.
Programmers and computer scientists have been buzzing for the past week about the latest attempt to solve one of the most vexing questions in computer science: the so-called "P versus NP problem."
Vinay Deolalikar, a research scientist at HP Labs in Palo Alto, CA, posted his "proof" online and sent it to several experts in the field on August 6. Colleagues immediately began dissecting the proof on academic blogs and wikis. Early reactions were respectful but skeptical, and the current consensus is that Deolalikar's approach is fundamentally flawed.
A solid proof would earn Deolalikar fame and fortune. The Clay Mathematics Institute in Cambridge, MA, has named "P versus NP" as one of its "Millennium" problems, and offers $1 million to anyone who provides a verified proof.
But "P versus NP" is more than just an abstract mathematical puzzle. It seeks to determine--once and for all--which kinds of problems can be solved by computers, and which kinds cannot. "P"-class problems are "easy" for computers to solve; that is, solutions to these problems can be computed in a reasonable amount of time compared to the complexity of the problem. Meanwhile, for "NP" problems, a solution might be very hard to find--perhaps requiring billions of years' worth of computation--but once found, it is easily checked. (Imagine a jigsaw puzzle: finding the right arrangement of pieces is difficult, but you can tell when the puzzle is finished correctly just by looking at it.)
NP-class problems include many pattern-matching and optimization problems that are of great practical interest, such as determining the optimal arrangement of transistors on a silicon chip, developing accurate financial-forecasting models, or analyzing protein-folding behavior in a cell.
The "P versus NP problem" asks whether these two classes are actually identical; that is, whether every NP problem is also a P problem. If P equals NP, every NP problem would contain a hidden shortcut, allowing computers to quickly find perfect solutions to them. But if P does not equal NP, then no such shortcuts exist, and computers' problem-solving powers will remain fundamentally and permanently limited. Practical experience overwhelmingly suggests that P does not equal NP. But until someone provides a sound mathematical proof, the validity of the assumption remains open to question.
Even if Deolalikar's proof were found to be sound, then the question remains--what impact would such a proof have on relevant areas of computing?
Superficially, one might think the answer is "not much." "Proving that P does not equal NP would just confirm what almost everyone already assumes to be true for practical purposes," explains Scott Aaronson, a complexity researcher at MIT's Computer Science and Artificial Intelligence Laboratory.
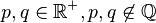 使 得
使 得 。 定义集(贝亚蒂列)
。 定义集(贝亚蒂列) , 则P 和 Q 构成正整数集的一个分划:
, 则P 和 Q 构成正整数集的一个分划: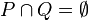 ,
, 。
。